Introduzione
Il presente report è il prodotto di un’attività di Threat Intelligence, basata su analisi passive e metodologia OSINT (Open Source INTelligence). A ciò è stata aggiunta la capacità di Almaviva Cybersecurity di correlare un set aggiuntivo di dati CLOSINT, consentendo una raccolta di informazioni non invasiva e non impattante sulla corretta funzionalità dei servizi analizzati.
Rapporto esecutivo
Nell’ambito delle attività di Security Research, il team Cybersecurity di Almaviva ha rilevato una vulnerabilità nel meccanismo di autenticazione del Googlebot, che consente ad utenti malintenzionati, di ingannare il motore di ricerca, inserendo nelle SERP (Search Engine Results Page) contenuti malevoli, quindi esponendo gli utenti che ricercano contenuti su Internet a risorse non adeguatamente verificate.
È noto, infatti, che Google abbia tra le sue priorità la Cybersecurity, come dimostrato in vari progetti, tra cui Google Safe Browsing, tuttavia, è stata rilevata la presenza di estese reti di siti web correttamente indicizzati e proposti agli utenti, che ingannano i sistemi di verifica di Google.
La vulnerabilità è presente nel meccanismo di autenticazione del Googlebot, lo strumento usato da Google per navigare su Internet, raccogliere i contenuti dei siti web, verificarli ed inserirli nella propria base dati.
Googlebot adotta una politica che prevede che lui stesso si identifichi sui sistemi a cui accede, per consentire ai proprietari dei siti di tracciarne la navigazione, ciò al fine di consentire ai proprietari dei siti una corretta Data Analytics ed altre attività di marketing. Il marketing è un aspetto fondamentale per Google in quanto rappresenta una primaria fonte di entrate, tramite i servizi di AdSense e AdWords.
Googlebot si identifica sui siti web in cui naviga, utilizzando le seguenti due tecniche:
- User-agent
- DNS Lookup
La prima tecnica, lo User-agent, prevede che Googlebot invii nelle richieste HTTP una intestazione predefinita, tra cui:
Mozilla/5.0 (Linux; Android 5.0; SM-G920A) AppleWebKit (KHTML, like Gecko) Chrome Mobile Safari (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html)
Per maggiori dettagli sugli User-agent predefiniti di Google, consultare la pagina ufficiale:
https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers
La seconda tecnica, il DNS Lookup, prevede che Googlebot invii le sue richieste esclusivamente utilizzando IP, la cui associazione, tramite IP Lookup (o DNS Reverse Lookup), sia Googlebot.com o Google.com. Da notare che Google non fornisce librerie software che consentono di identificare i suoi crawler e pertanto consiglia, in modo probabilmente anche ironico ed in fondo alla pagina ufficiale di seguito riportata, di ricercare una libreria open source:

Il link ufficiale indicato da Google è il seguente: https://www.google.com/search?q=googlebot+detection+library
Per maggiori dettagli sulla verifica di Google tramite DNS Lookup, consultare la pagina ufficiale:
https://developers.google.com/search/docs/advanced/crawling/verifying-googlebot
Ricercando quindi come proposto da Google, una soluzione open source, è stata trovata la seguente guida:
https://www.holisticseo.digital/python-seo/dns-reverse-lookup/
Si riporta di seguito il codice sorgente della soluzione proposta:
try:
reversed_dns = socket.gethostbyaddr(row)
if str.__contains__(reversed_dns[0], 'googlebot.com') or str.__contains__(reversed_dns[0],
'google.com'):
temp_ip = socket.gethostbyaddr(str(reversed_dns[2]).strip("'[]'"))
if reversed_dns == temp_ip:
googlebot.append(reversed_dns[0])
else:
nongooglebot.append(reversed_dns[0])
else:
nongooglebot.append(reversed_dns[0])
except:
pass
csvfile.close()Tale codice è stato analizzato ed è risultato vulnerabile a sua volta, questo ha consentito al team di Almaviva di aggirare anche questa ulteriore verifica. Tale vulnerabilità, tuttavia, non sarà oggetto di questo articolo in quanto consente ad Almaviva di simulare Googlebot in modo efficace e di analizzare approfonditamente le minacce veicolate dai siti web malevoli indicizzati nelle SERP, su cui Google ad oggi non interviene.
Rapporto tecnico
Ogni vulnerabilità per poter essere definita tale necessita di alcuni elementi imprescindibili: bug, exploit, fix, workaround ed un proof of concept, pertanto si riportano di seguito, dettagliatamente, tali elementi.
Bug
Googlebot identifica sé stesso sui siti web per consentire la Data Analytics, tramite user agent e Reverse DNS Lookup. Questo meccanismo di autenticazione consente ad un sito malintenzionato di mostrare un contenuto legittimo a Googlebot per poter essere indicizzato e reso raggiungibile agli utenti, ed un contenuto malevolo al tempo stesso per gli utenti.
Exploit
Il sistema di identificazione di Googlebot può essere utilizzato per creare una condizione secondo cui, se i contenuti sono visualizzati da Google, allora sono legittimi, se invece i contenuti sono visualizzati dagli utenti allora i contenuti presentano la minaccia.
Si riporta di seguito il codice per l’exploiting basato intenzionalmente sul codice sorgente sopra esposto, dunque principalmente a scopo illustrativo, non funzionale:
# [...]
def is_google_bot(request):
user_agent = get_user_agent(request)
ip = get_ip(request)
try:
reversed_dns = reverse(ip)
if str.__contains__(reversed_dns, 'googlebot.com') or str.__contains__(reversed_dns, 'google.com') and user_agent.is_bot:
return true # no_threat_active
else:
return false # threat_active
# [...]Fix
Adozione di un sistema di verifica dei contenuti simulando un utente, quindi non identificandosi come Googlebot per opportune verifiche dei contenuti.
Workaround
Adozione di un Threat Intelligence Data Feed che consenti di enumerare tali minacce, procedendo così al blocco della navigazione dei propri utenti e all’esecuzione dei Takedown. Per maggiori dettagli info@cyberiskvision.com
Proof of concept
Di seguito si riportano le evidenze raccolte durante le analisi, in particolare la SERP inquinata di Google:
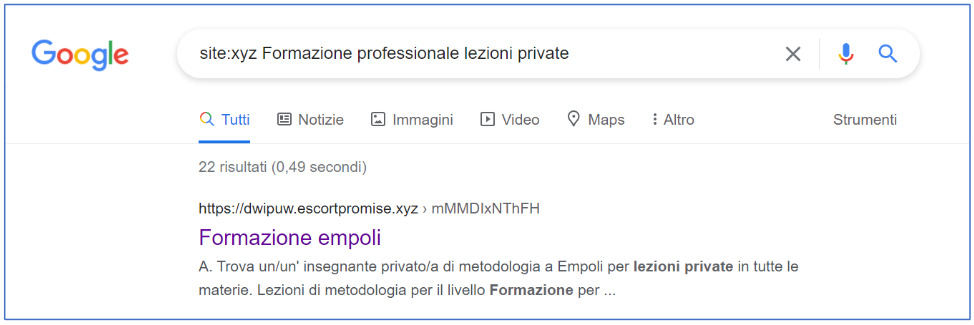
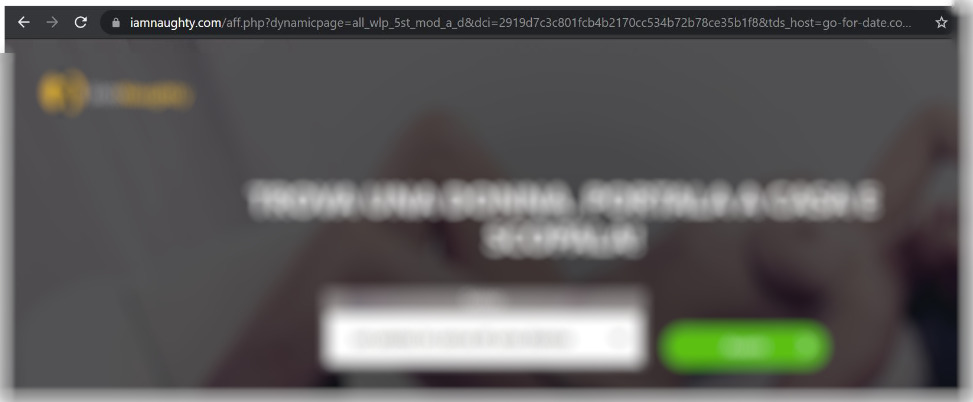
Apparentemente il primo sito consente di trovare un insegnante privato ad Empoli per lezioni private, ma accedendo, il sito è diverso da quanto mostrato a Googlebot, infatti:
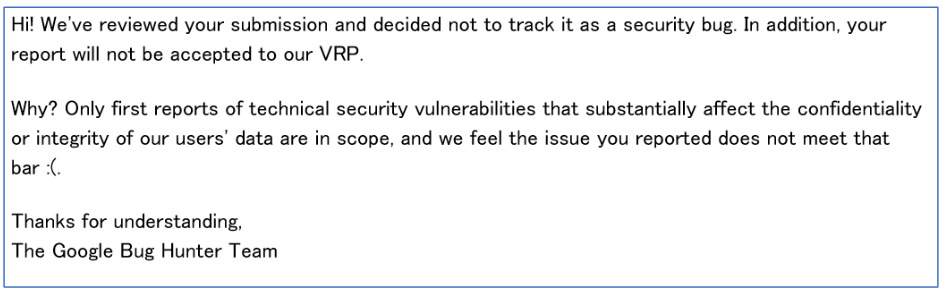
La risposta di Google
Contattato Google, ha affermato, che tale minaccia non influenza sostanzialmente la riservatezza o l’integrità dei dati dei suoi utenti, pertanto non procederà alla gestione di tale problematica né fornirà un codice identificativo. Di seguito è riportata la risposta integrale in quanto priva di dati personali e/o confidenziali:
Common Vulnerability Scoring System
CVSS Score: 6.1
CVSS Vector: AV:N/AC:L/PR:N/UI:R/S:C/C:L/I:L/A:N/E:H/RL:U/RC:C
Common Vulnerabilities and Exposures
Ad oggi tale vulnerabilità non dispone di una codice identificativo CVE (Common Vulnerabilities and Exposures) in quanto tale sistema di tracciamento delle vulnerabilità prevede la generazione di un CVE ID direttamente da parte di Google, e pertanto, anche il Mitre, in base al proprio processo, seppur informato del disinteresse di Google alla gestione di tale segnalazione, non ha reso disponibile una CVE ID.
Per maggiori dettagli: https://cve.mitre.org/cve/request_id.html#g
Si rende pertanto disponibile per la tracciatura di questa vulnerabilità il seguente codice identificativo generato dal sistema Joshua CybeRisk Vision: JCV-2021.08.05.01.