Calcolo del rischio e previsione dell’impatto
Per fronteggiare un numero crescente di vulnerabilità distribuite su sistemi eterogenei e in continuo aggiornamento, la complessità non risiede esclusivamente nel rilevarle, ma nel valutarle e comprendere quali rappresentano una minaccia reale, quindi definire una efficace priorità d’intervento.
I sistemi di ricerca delle vulnerabilità offrono indicazioni su metriche consolidate (es: Common Vulnerability Scoring System, CVSS), che misurano la gravità di una vulnerabilità, ma non considerano le probabilità reali di exploit, infatti, per condividere un esempio, non tutte le vulnerabilità con CVSS alto vengono sfruttate, e viceversa: alcune con punteggi medi possono diventare vettori di attacco significativi se emergono exploit pubblici, mediante campagne attive.
Per colmare questo divario, il Cyber Threat Defence Center di Almaviva ha adottato una metrica predittiva basata sul machine learning, in grado di stimare la probabilità reale di sfruttamento di una vulnerabilità (exploiting).
Tale metrica adotta un algoritmo robusto e versatile per l’analisi predittiva su dati complessi non lineari, denominato Extreme Gradient Boosting (XGBoost).
Apprendimento adattivo del rischio
La soluzione adottata è in grado di imparare dai propri errori e, a differenza dei modelli statici che applicano regole fisse, XGBoost costruisce una sequenza di alberi decisionali (decision trees), ognuno dei quali viene addestrato per correggere gli errori del precedente.
Questo processo iterativo, chiamato boosting, consente di combinare modelli semplici in una struttura complessiva più efficace, capace di catturare relazioni complesse tra le variabili.
In pratica, ad ogni passaggio il modello valuta quanto le sue predizioni si discostano dai dati reali e aggiorna i pesi interni per ridurre l’errore complessivo.
L’obiettivo è migliorare progressivamente la precisione del modello, creando una rete di decisioni ottimizzate.
Questa capacità adattiva rende XGBoost particolarmente compatibile al dominio della cybersecurity, dove le relazioni tra vulnerabilità, exploit e comportamenti di attacco sono spesso non lineari e difficili da modellare in modo tradizionale.
La perdita logistica
Per stimare la probabilità che una vulnerabilità venga sfruttata, XGBoost utilizza una funzione di perdita logistica (logistic loss function), ideale per problemi di classificazione binaria, in cui il risultato può essere “sì/no” — in questo caso, “sfruttata/non sfruttata”.
La funzione è definita come:
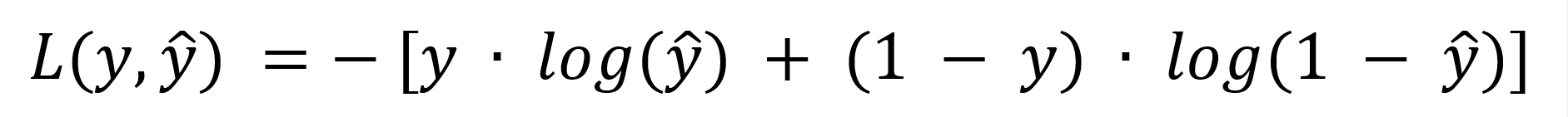
dove:
- y rappresenta il valore reale osservato (1 se la vulnerabilità è stata effettivamente sfruttata, 0 se non lo è stata);
- ŷ è la probabilità predetta dal modello, compresa tra 0 e 1.
Il principio è intuitivo: più il valore predetto si discosta dal risultato reale, maggiore è la “penalità” assegnata.
L’algoritmo cerca di minimizzare la somma di tutte queste penalità sull’intero set di dati, correggendo iterativamente i pesi interni per migliorare le previsioni.
Nel contesto della metrica qui presa in considerazione, questa funzione consente al modello di affinare progressivamente la propria capacità di distinguere le vulnerabilità a rischio reale da quelle con bassa probabilità di sfruttamento, anche quando i dati disponibili sono rumorosi o incompleti.
Gli elementi considerati dalla metrica
L’efficacia predittiva del modello dipende fortemente dalla qualità ed eterogeneità delle variabili su cui viene allenato.
La metrica adottata si basa su un insieme complesso dei dati, che combinano aspetti tecnici, contestuali e comportamentali.
Tra le principali categorie di variabili utilizzate figurano:
- Metadati tecnici, come il punteggio CVSS, la classificazione CWE e la data di pubblicazione del CVE. Questi elementi forniscono una base strutturata di informazioni sulla vulnerabilità.
- Indicatori di minaccia attiva, come la presenza di indicatori all’interno di fonti OSINT (es. CISA KEV). Questi dati segnalano se una vulnerabilità è già nota per essere sfruttata o monitorata.
- Exploit pubblici, presenti nei primari repository (es: ExploitDB, GitHub, Metasploit) che rappresentano un segnale concreto di rischio operativo.
- Segnali social e reputazionali, come menzioni su piattaforme specialistiche o social network tecnici. Queste informazioni catturano l’attenzione della community di sicurezza e possono anticipare l’emergere di exploit attivi.
L’algoritmo XGBoost analizza queste feature in combinazione, identificando correlazioni e pattern ricorrenti che suggeriscono quando una vulnerabilità è più suscettibile di essere sfruttata.
Il risultato è una metrica che restituisce un valore probabilistico chiaro e interpretabile, utile per guidare le decisioni operative.
Trasparenza decisionale
La normativa europea (AI Act) richiede trasparenza e spiegabilità delle decisioni prese dagli algoritmi predittivi, questo requisito è stato soddisfatto tramite l’uso dei valori SHAP (SHapley Additive exPlanations), un metodo derivato dalla teoria dei giochi che consente di quantificare il contributo di ciascuna variabile alla predizione finale.
La relazione generale può essere rappresentata come:
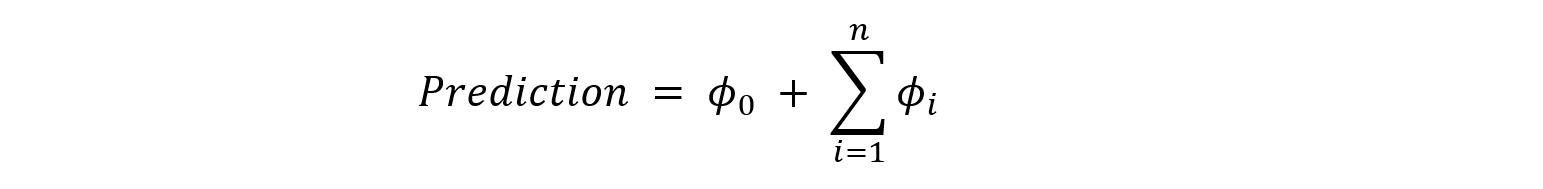
dove:
- ϕ0 è il valore medio di riferimento (baseline), ovvero la probabilità media di rischio su tutto il dataset;
- ϕi rappresenta il contributo della singola variabile i-esima alla predizione.
In pratica, i valori SHAP rendono il modello “trasparente”: permettono di capire, per ogni vulnerabilità, quali fattori hanno inciso maggiormente nell’aumentare o ridurre la probabilità di sfruttamento.
Di seguito un esempio:
- Valore medio di partenza = 0.50
- Contributi SHAP:
- CVSS alto → +0.10
- Exploit su GitHub → +0.15
- Età della CVE (recente) → +0.05
Totale: 0.50 + 0.10 + 0.15 + 0.05 = 0.80
Conclusioni
L’integrazione di una metrica predittiva di exploiting rappresenta un elemento distintivo e di elevato valore aggiunto all’interno dei Servizi e dei Prodotti del Cyber Threat Defence Center di Almaviva, in particolare in ambito Intelligence e Security Assessment.
Questa metrica consente di quantificare la probabilità di sfruttamento reale di una vulnerabilità, superando l’approccio puramente descrittivo basato su indici di gravità statici (es. CVSS). L’analisi predittiva, ottenuta attraverso modelli di machine learning e correlazioni multi-sorgente (exploit pubblici, trend di threat actor, indicatori di weaponization), permette di anticipare gli scenari di rischio con un livello di accuratezza maggiore.
L’adozione di tale metodologia rende i report di Security Assessment orientati all’azione: ogni vulnerabilità non viene solo classificata in base alla criticità teorica, ma anche valutata per la probabilità concreta di essere sfruttata in un determinato orizzonte temporale. Ciò consente ai nostri clienti di prioritizzare in modo oggettivo gli interventi di remediation, riducendo sensibilmente tempi e costi di risposta.
La presenza della metrica predittiva di exploiting consolida un approccio data-driven e proattivo alla gestione della sicurezza, allineato alle best practice internazionali (MITRE ATT&CK, NIST SP 800-30, ISO/IEC 27005). Tale innovazione metodologica rappresenta un passo decisivo verso una cyber resilience misurabile, predittiva e sostenibile.